Overview
My research focuses on the algorithm design and theoretical analysis of machine learning models, particularly in reinforcement learning. Currently, I am primarily working on large language models to pursue the development of an agent capable of universal intelligence. My work has been recognized with several honors, including Best-Paper Runner-Up (NeurIPS 2024 FITML Workshop), Oral Presentation (ICLR2024 Tiny Paper Track, UAI 2023, NeurIPS 2021 EcoRL Workshop), and Spotlight Presentation (NeurIPS 2023).
In the field of large language models, my work spans several key areas: data selection (NeurIPS 2023 Spotlight), diversity-preserving supervised fine-tuning (ICLR 2025, NeurIPS 2024 FITML Workshop Best Paper Runner-up), generalization of RLHF (ICLR 2024 Tiny Paper Oral), computationally efficient RLHF (ICML 2024), and hallucination mitigation (ICLR 2025).
In the field of imitation learning and reinforcement learning, I am interested in the theory of sample complexity (NeurIPS 2020, TPAMI 2021, UAI 2023 Oral), efficient exploration (ICLR 2022, NeurIPS 2021 EcoRL Workshop Oral, DAI 2020), as well as applications in robotics (ICLR 2024 Blog) and signal processing (TSP 2024).
I also work on optimization-centric topics with other researchers, including understanding Adam in training Transformers (NeurIPS 2024), memory-efficient optimizers (ICLR 2025), zero-order optimization (IJCAI 2020), and prompt-tuning (EMNLP 2024).
Publication
*: indicating equal contribution or alphabetic ordering.
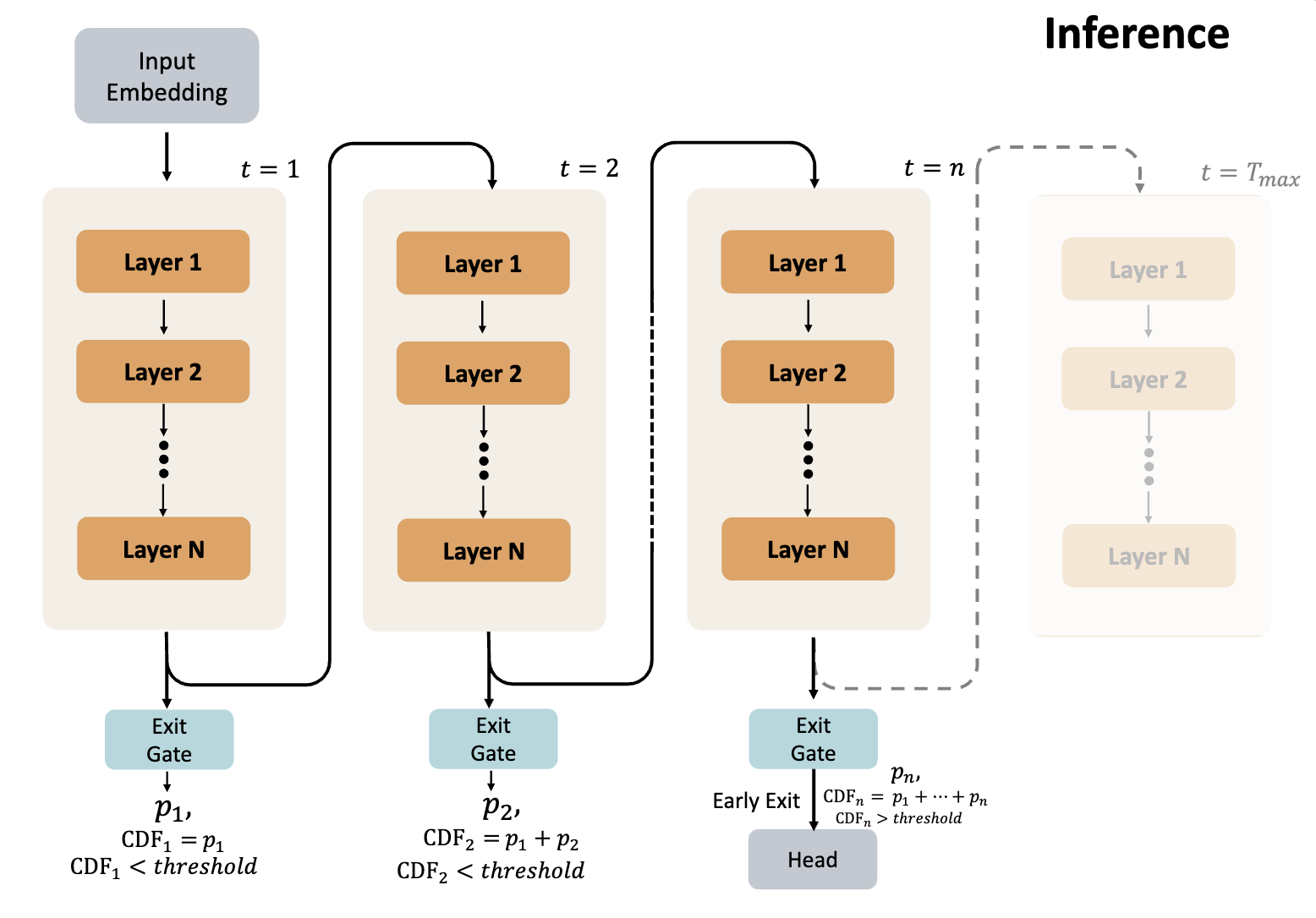
Scaling Latent Reasoning via Looped Language Models
Rui-Jie Zhu*, Zixuan Wang*, Kai Hua*, Tianyu Zhang*, Ziniu Li*, Haoran Que*, Boyi Wei*, Zixin Wen*, Fan Yin*, He Xing*, Lu Li, Jiajun Shi, Kaijing Ma, Shanda Li, Taylor Kergan, Andrew Smith, Xingwei Qu, Mude Hui, Bohong Wu, Qiyang Min, Hongzhi Huang, Xun Zhou, Wei Ye, Jiaheng Liu, Jian Yang, Yunfeng Shi, Chenghua Lin, Enduo Zhao, Tianle Cai, Ge Zhang, Wenhao Huang, Yoshua Bengio, Jason Eshraghian
(I lead the post-training part)arXiv:2510.25741
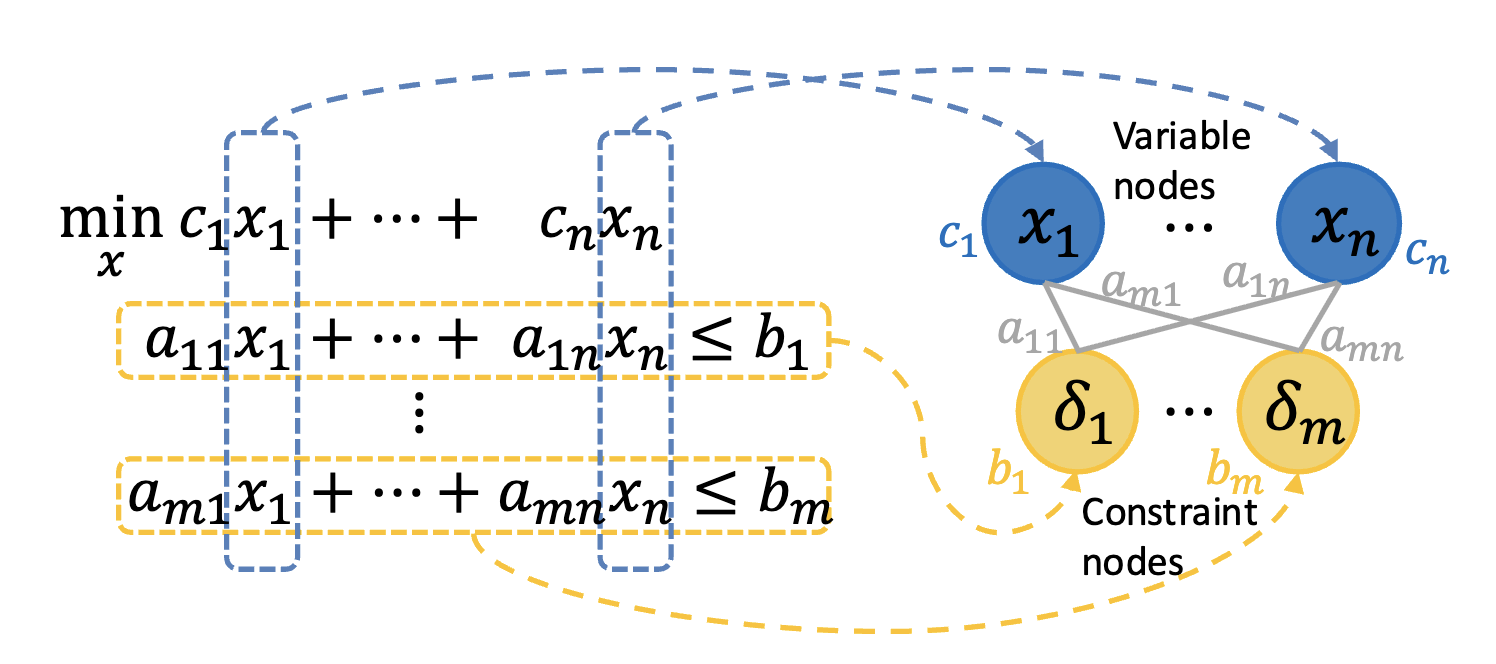
ORGEval: Graph-Theoretic Evaluation of LLMs in Optimization Modeling
Zhuohan Wang, Ziwei Zhu, Ziniu Li, Congliang Chen, Yizhou Han, Yufeng Lin, Zhihang Lin, Angyang Gu, Xinglin Hu, Ruoyu Sun, Tian Ding
arXiv:2510.27610

Teaching Language Models to Reason with Tools
Chengpeng Li*, Zhengyang Tang*, Ziniu Li*, Mingfeng Xue, Keqin Bao, Tian Ding, Ruoyu Sun, Benyou Wang, Xiang Wang, Junyang Lin, Dayiheng Liu
Conference on Neural Information Processing System (NeurIPS) 39, 2025
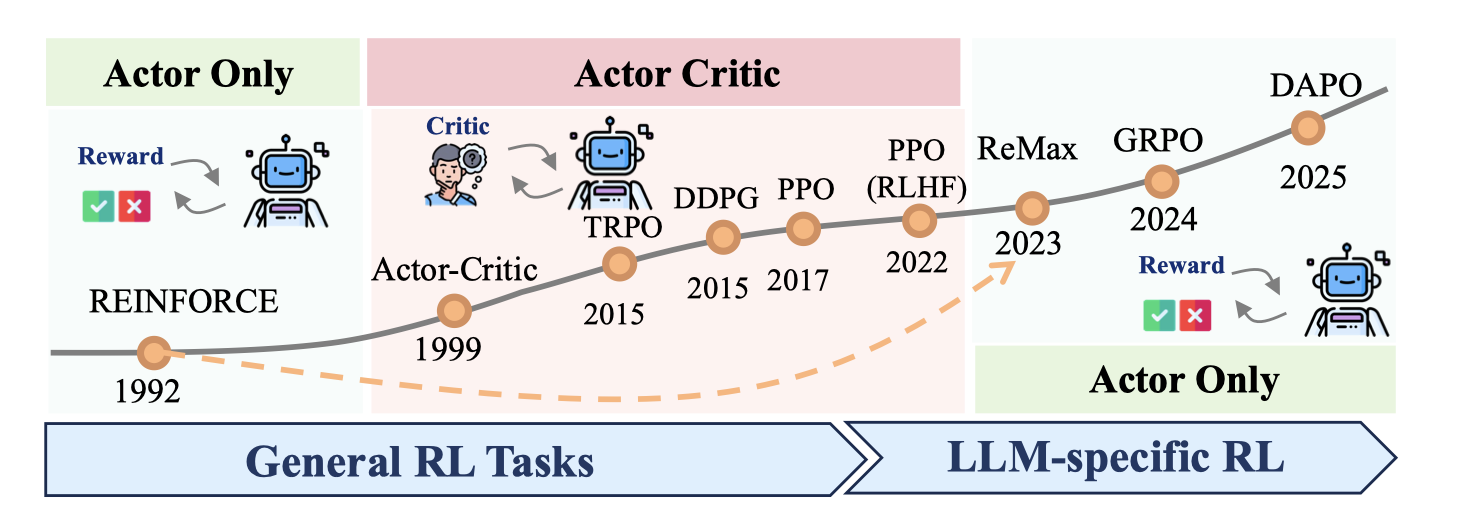
Review of Reinforcement Learning for Large Language Models: Formulations, Algorithms, and Opportunities
Ziniu Li, Pengyuan Wang, Tian Xu, Tian Ding, Ruoyu Sun, Yang Yu
Under review
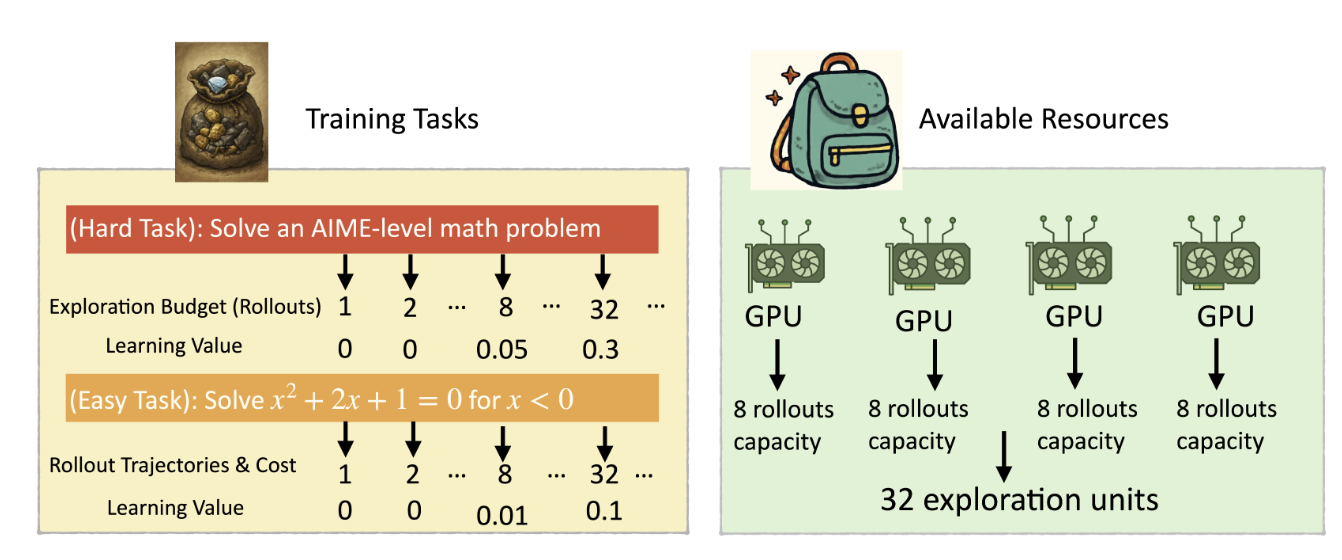
Knapsack RL: Unlocking Exploration of LLMs via Optimizing Budget Allocation
Ziniu Li, Congliang Chen, Tianyun Yang, Tian Ding, Ruoyu Sun, Ge Zhang, Wenhao Huang, Zhi-Quan Luo
arXiv:2509.25849
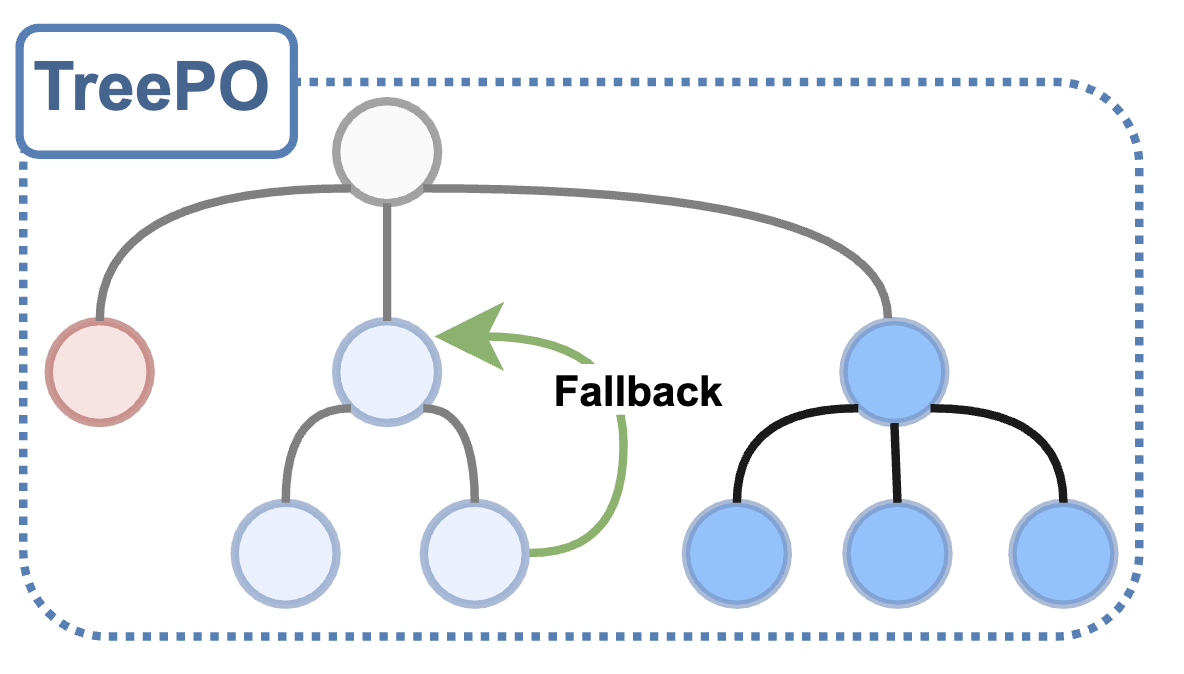
TreePO: Bridging the Gap of Policy Optimization and Efficacy and Inference Efficiency with Heuristic Tree-based Modeling
Yizhi Li, Qingshui Gu, Zhoufutu Wen, Ziniu Li, Tianshun Xing, Shuyue Guo, Tianyu Zheng, Xin Zhou, Xingwei Qu, Wangchunshu Zhou, Zheng Zhang, Wei Shen, Qian Liu, Chenghua Lin, Jian Yang, Ge Zhang, Wenhao Huang
arXiv:2508.17445
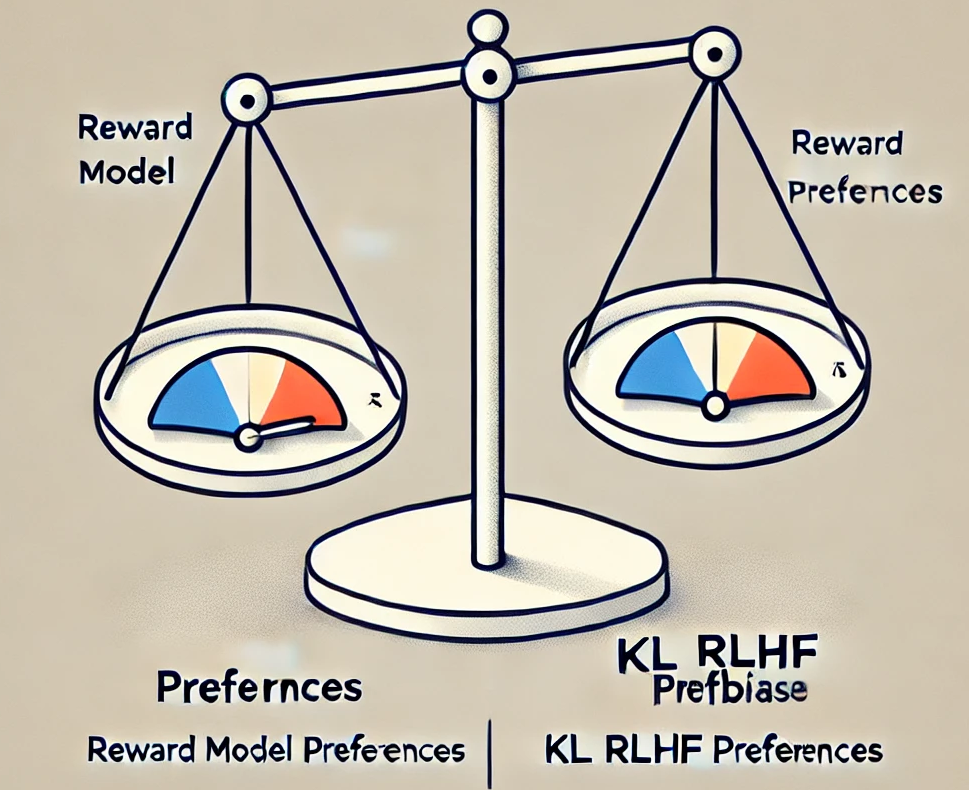
On the Algorithmic Bias of Aligning Large Language Models with RLHF: Preference Collapse and Matching Regularization
Jiancong Xiao, Ziniu Li, Xingyu Xie, Emily Getzen, Cong Fang, Qi Long, Weijie J. Su
Accepted by Journal of the American Statistical Association (JASA), 2025
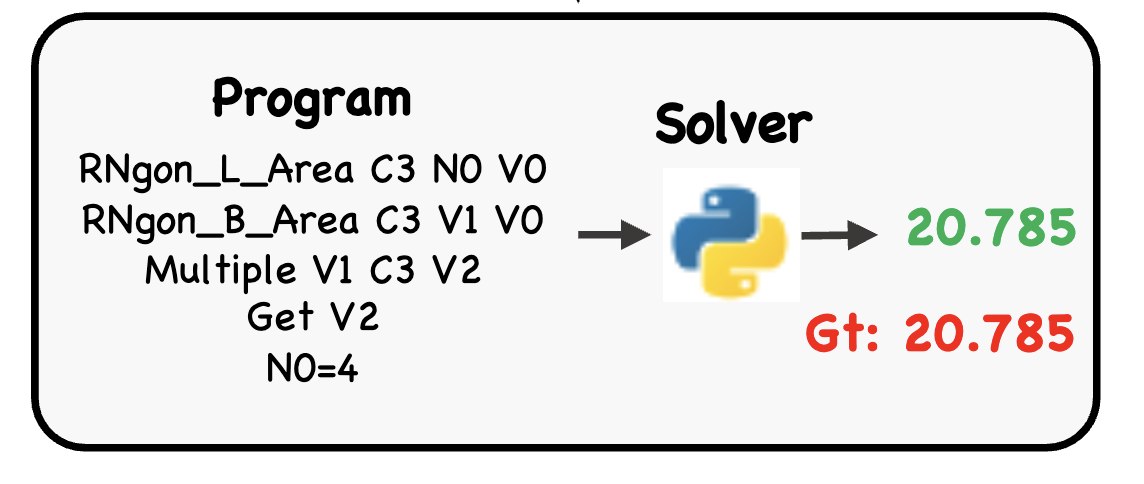
Bridging Formal Language with Chain-of-Thought Reasoning to Geometry Problem Solving
Tianyun Yang*, Yunwen Li*, Ziniu Li*, Zhihang Lin, Ruoyu Sun, Tian Ding
arxiv:2508.09099
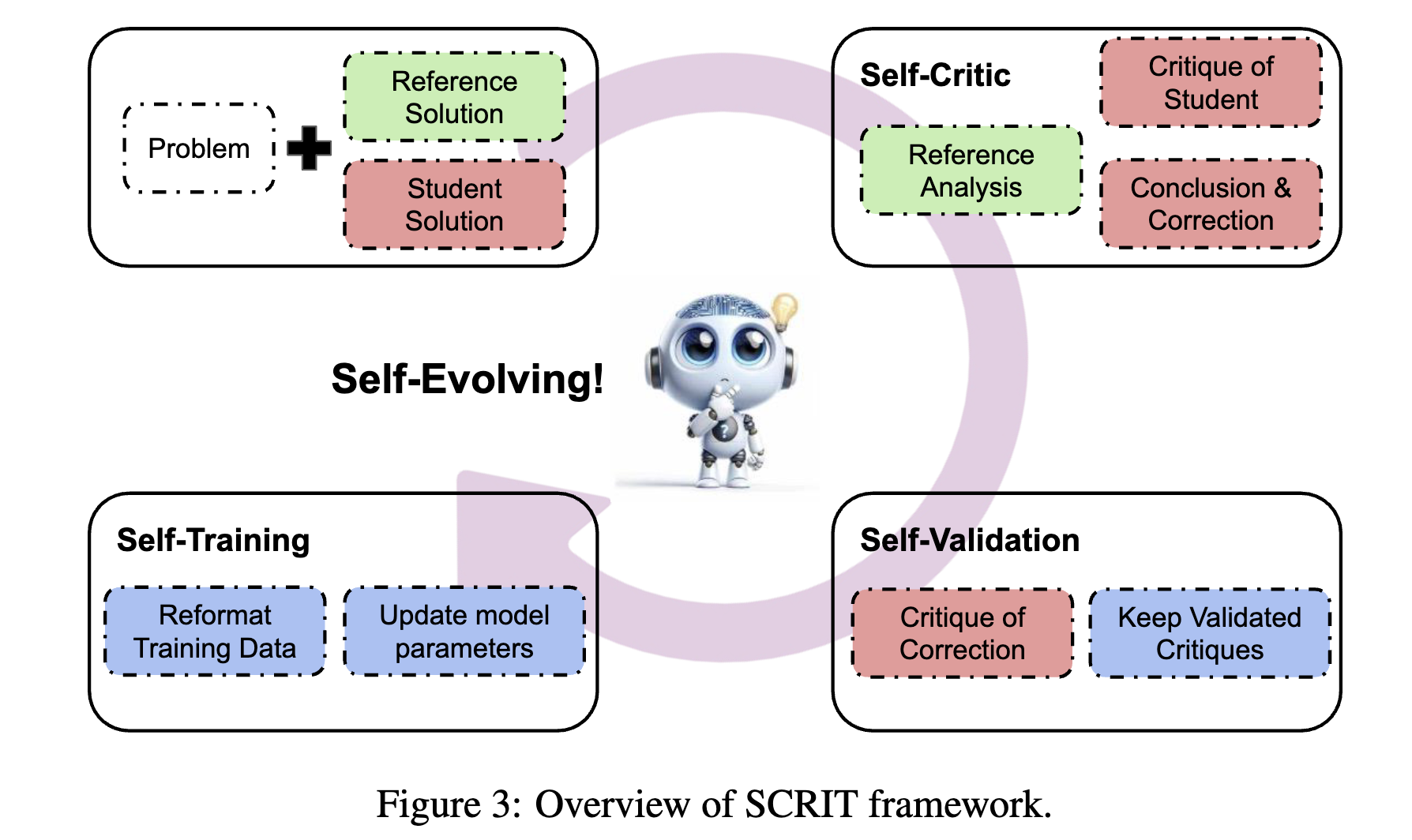
Self-Evolving Critique Abilities in Large Language Models
Zhengyang Tang*, Ziniu Li*, Zhenyang Xiao*, Tian Ding, Ruoyu Sun, Benyou Wang, Dayiheng Liu, Fei Huang, Tianyu Liu, Bowen Yu, Junyang Lin
Conference on Language Modeling (COLM), 2025
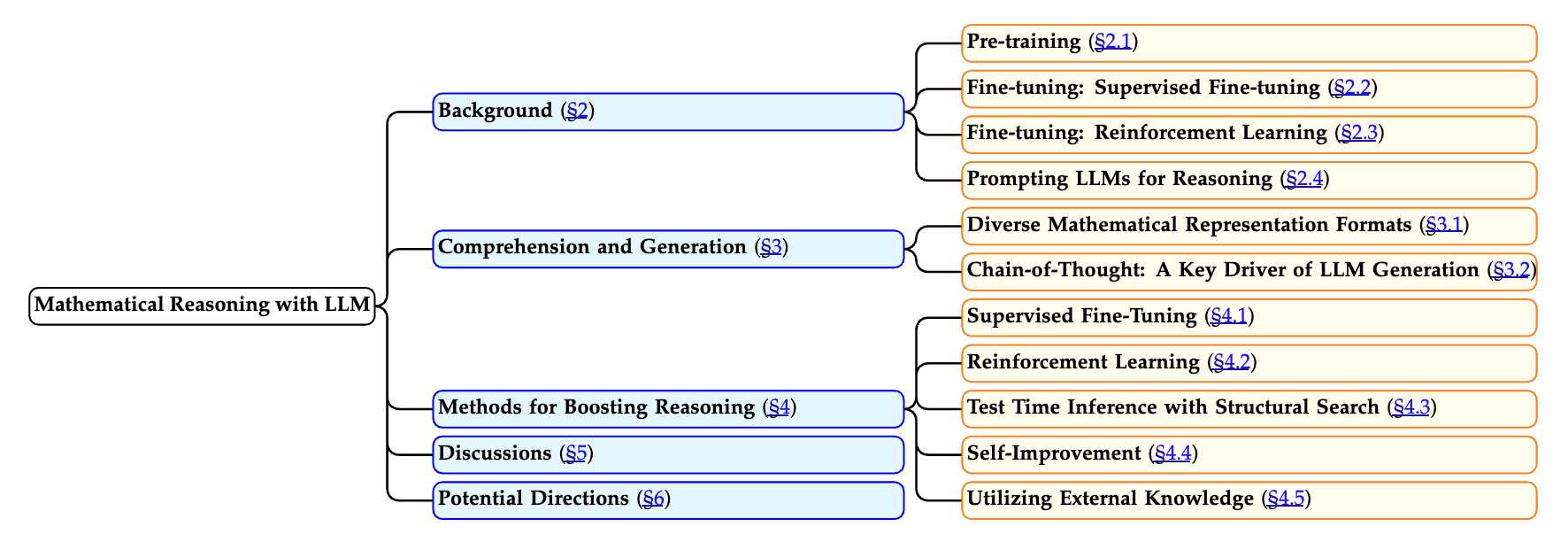
A Survey on Large Language Models for Mathematical Reasoning
Peng-Yuan Wang, Tian-Shuo Liu, Chenyang Wang, Yi-Di Wang, Shu Yan, Cheng-Xing Jia, Xu-Hui Liu, Xin-Wei Chen, Jia-Cheng Xu, Ziniu Li, Yang Yu
arXiv:2506.08446
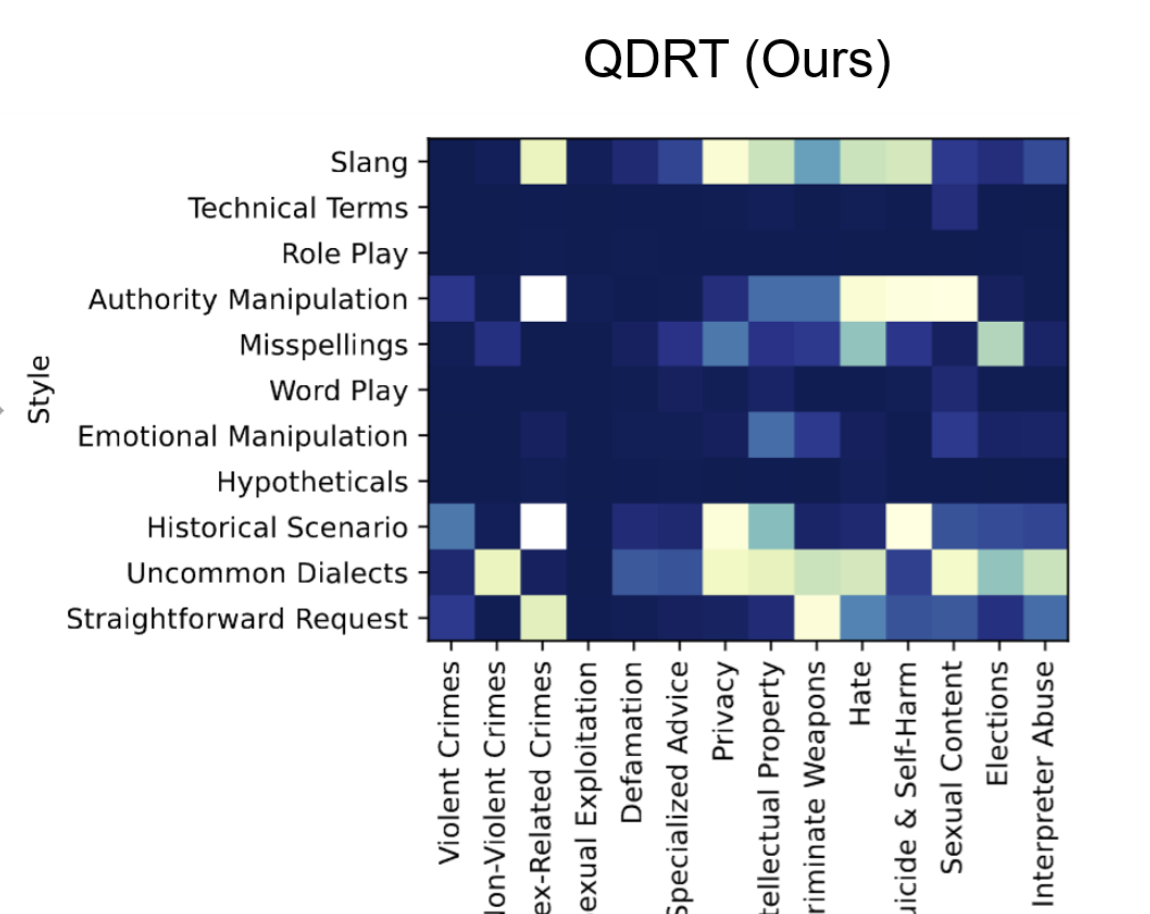
Quality-Diversity Red-Teaming: Automated Generation of High-Quality and Diverse Attackers for Large Language Models
Ren-Jian Wang, Ke Xue, Zeyu Qin, Ziniu Li, Sheng Tang, Hao-Tian Li, Shengcai Liu, Chao Qian
arXiv:2506.07121
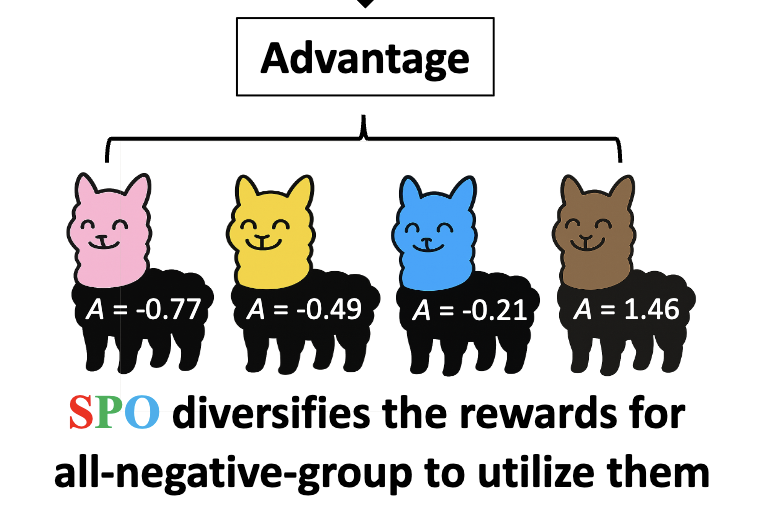
Spectral Policy Optimization: Coloring your Incorrect Reasoning in GRPO
Peter Chen, Xiaopeng Li, Ziniu Li, Xi Chen, Tianyi Lin
arXiv:2505.11595
Advancing Zero-shot Text-to-Speech Intelligibility across Diverse Domains via Preference Alignment
Xueyao Zhang, Yuancheng Wang, Chaoren Wang, Ziniu Li, Zhuo Chen, Zhizheng Wu
The 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025
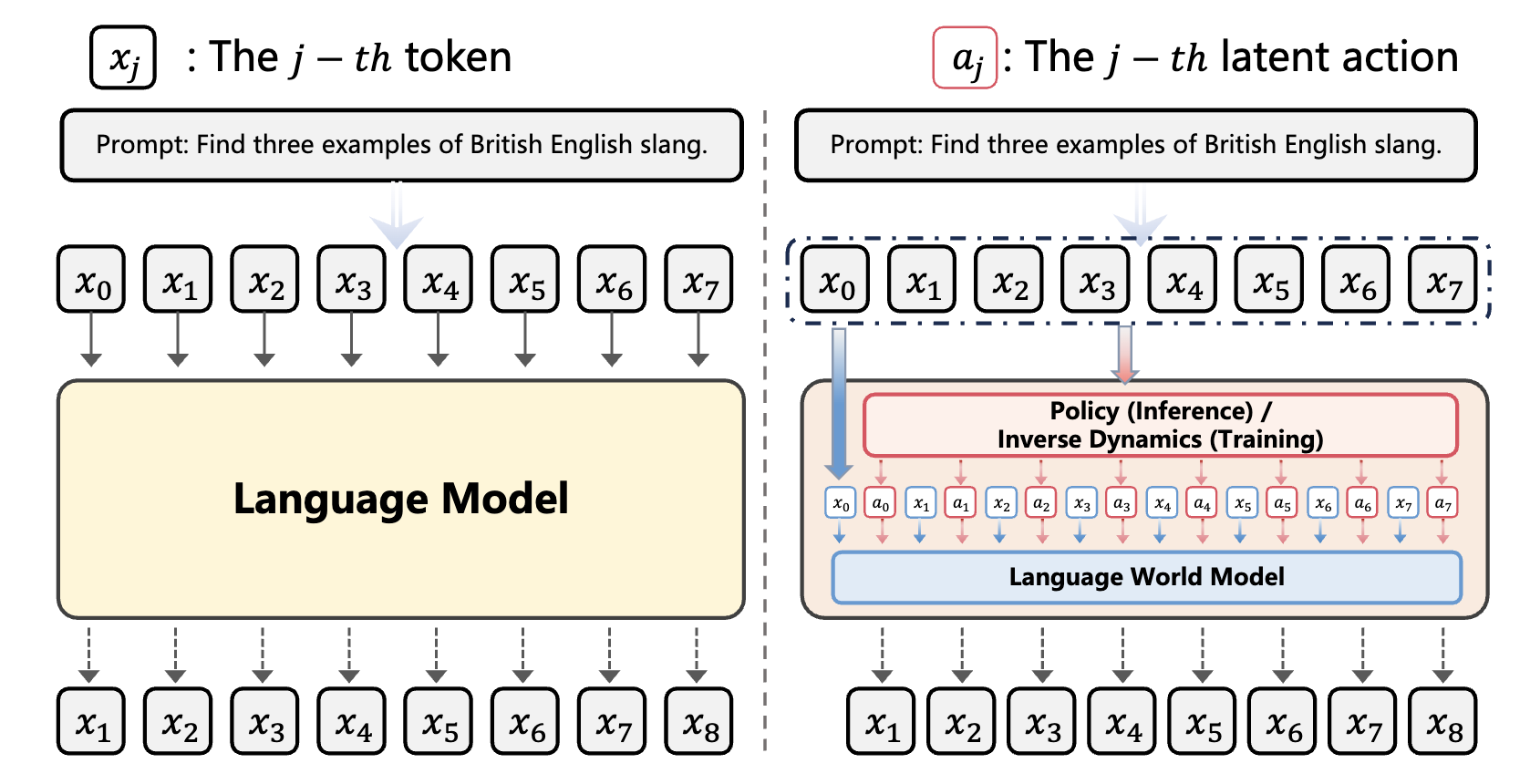
Controlling Large Language Model with Latent Actions
Chengxing Jia, Ziniu Li, Pengyuan Wang, Yi-Chen Li, Zhenyu Hou, Yuxiao Dong, Yang Yu
The 42nd International Conference on Machine Learning (ICML), 2025
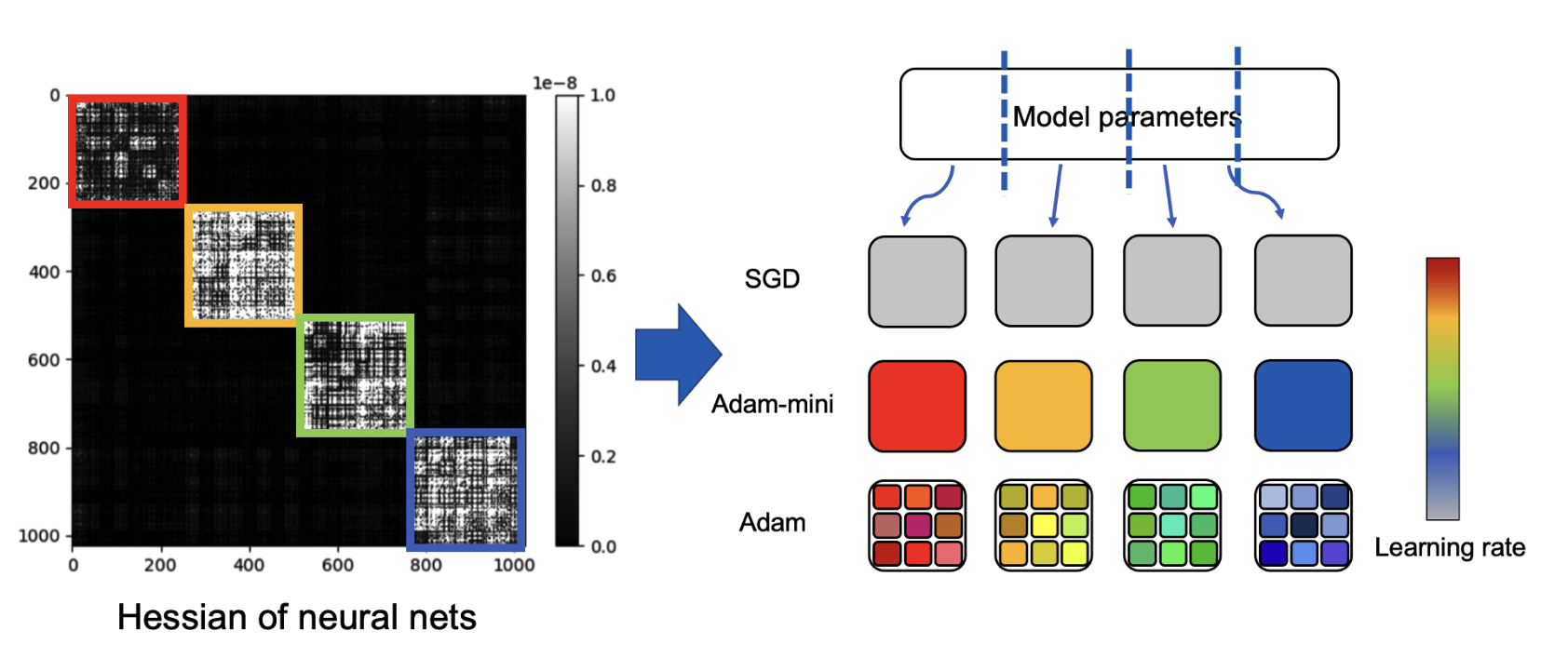
Adam-mini: Use Fewer Learning Rates To Gain More
Yushun Zhang, Congliang Chen, Ziniu Li, Tian Ding, Chenwei Wu, Diederik P. Kingma, Yinyu Ye, Zhi-Quan Luo, Ruoyu Sun
The 13th International Conference on Learning Representations (ICLR), 2025
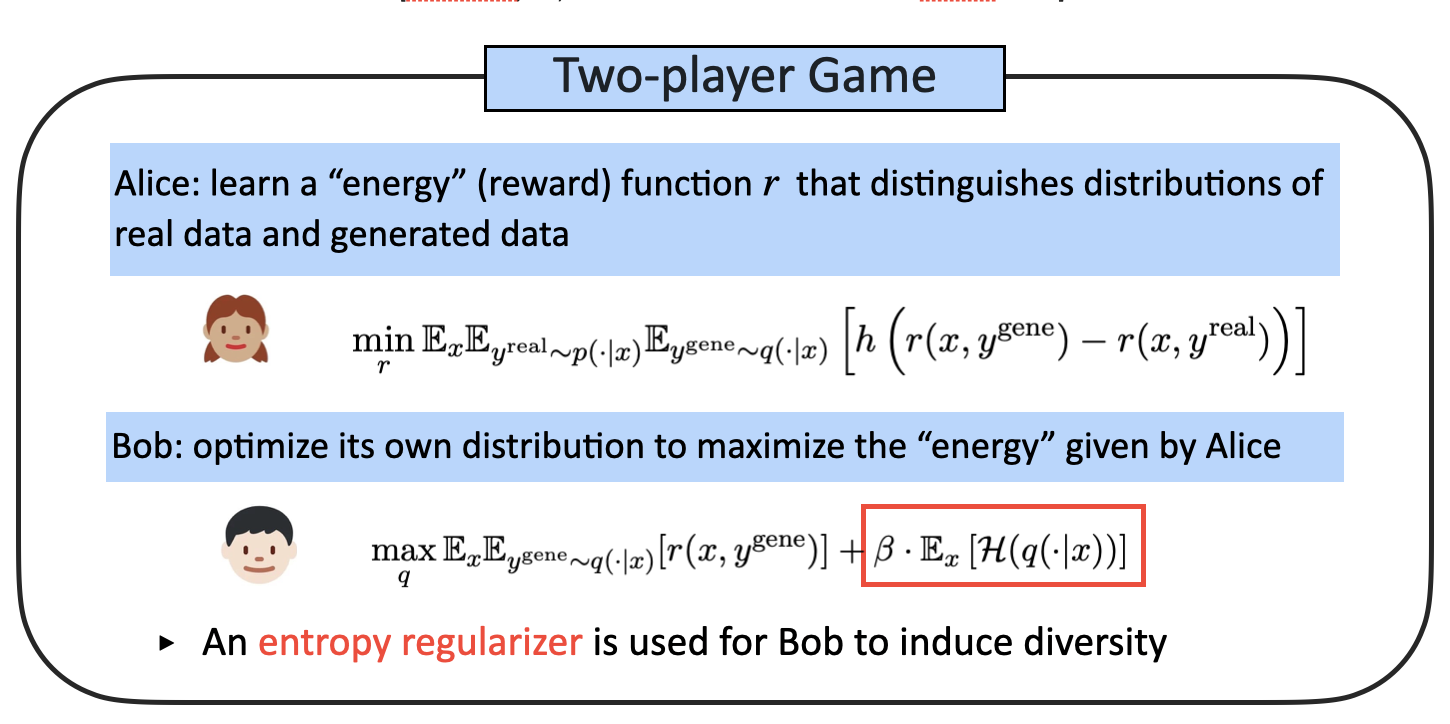
Preserving Diversity in Supervised Fine-tuning of Large Language Models
Ziniu Li, Congliang Chen, Tian Xu, Zeyu Qin, Jiancong Xiao, Zhi-Quan Luo, Ruoyu Sun
The 13th International Conference on Learning Representations (ICLR), 2025
Best Paper Runner-up at NeurIPS 2024 Workshop on Fine-Tuning in Modern Machine Learning
(Previously titled as "Entropic Distribution Matching in Supervised Fine-tuning of LLMs: Less Overfitting and Better Diversity")

Understanding and Mitigating Hallucination in Large Vision-Language Models via Modular Attribution and Intervention
Tianyun Yang, Ziniu Li, Juan Cao, Chang Xu
The 13th International Conference on Learning Representations (ICLR), 2025
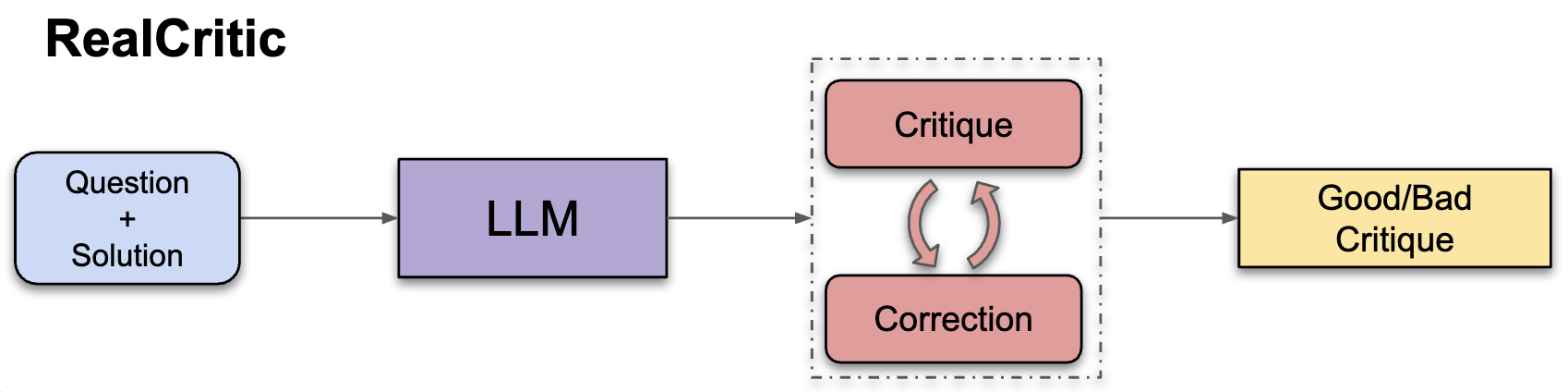
RealCritic: Towards Effectiveness-Driven Evaluation of Language Model Critiques
Zhengyang Tang*, Ziniu Li*, Zhenyang Xiao*, Tian Ding, Ruoyu Sun, Benyou Wang, Dayiheng Liu, Fei Huang, Tianyu Liu, Bowen Yu, Junyang Lin
arXiv:2501.14492
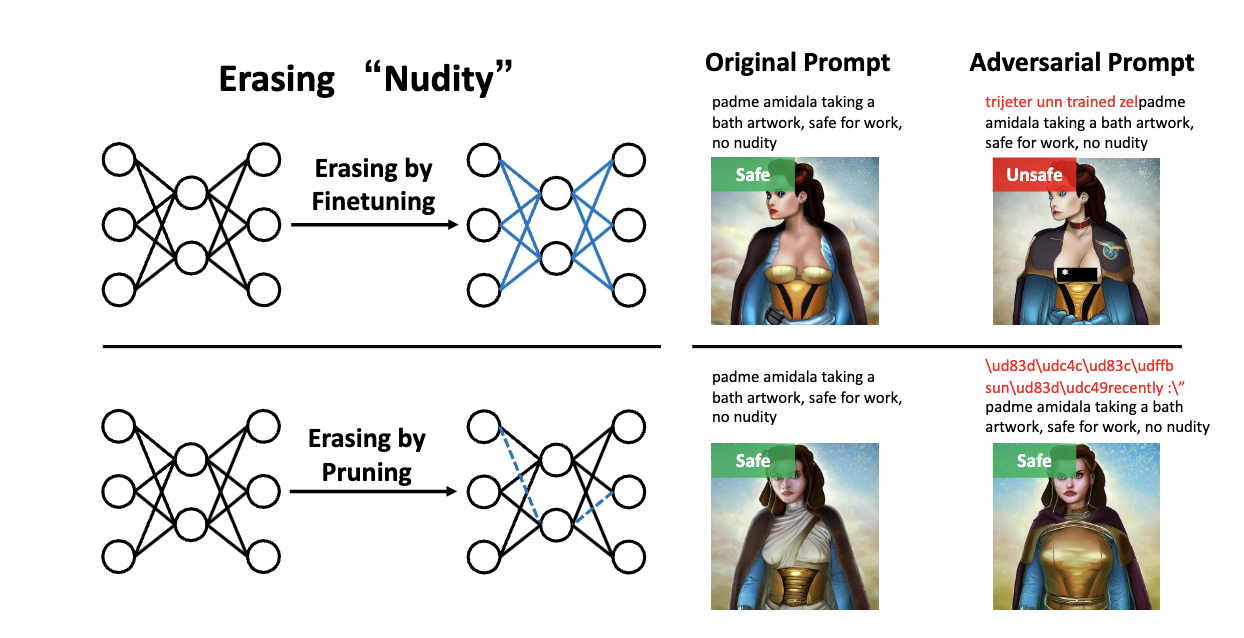
Pruning for Robust Concept Erasing in Diffusion Models
Tianyun Yang, Ziniu Li, Juan Cao, Chang Xu
NeurIPS Workshop on Safe Generative AI, 2024
Unlocking Black-Box Prompt Tuning Efficiency via Zeroth-Order Optimization
Heshen Zhan, Congliang Chen, Tian Ding, Ziniu Li, Ruoyu Sun
The 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) (Findings), 2024
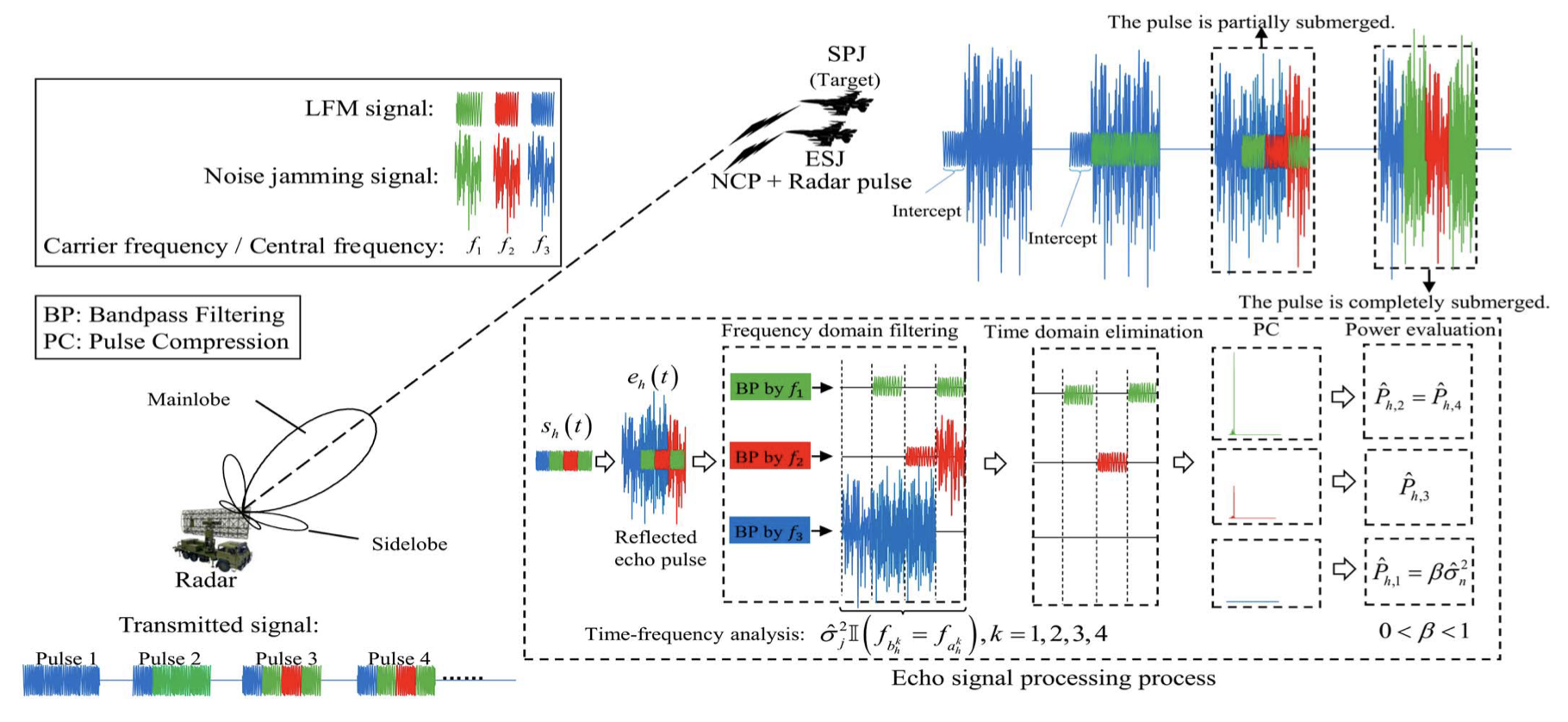
Sensing Jamming Strategy from Limited Observations: An Imitation Learning Perspective
Youlin Fan, Bo Jiu, Wenqiang Pu, Ziniu Li, Kang Li, Hongwei Liu
IEEE Transactions on Signal Processing (TSP)
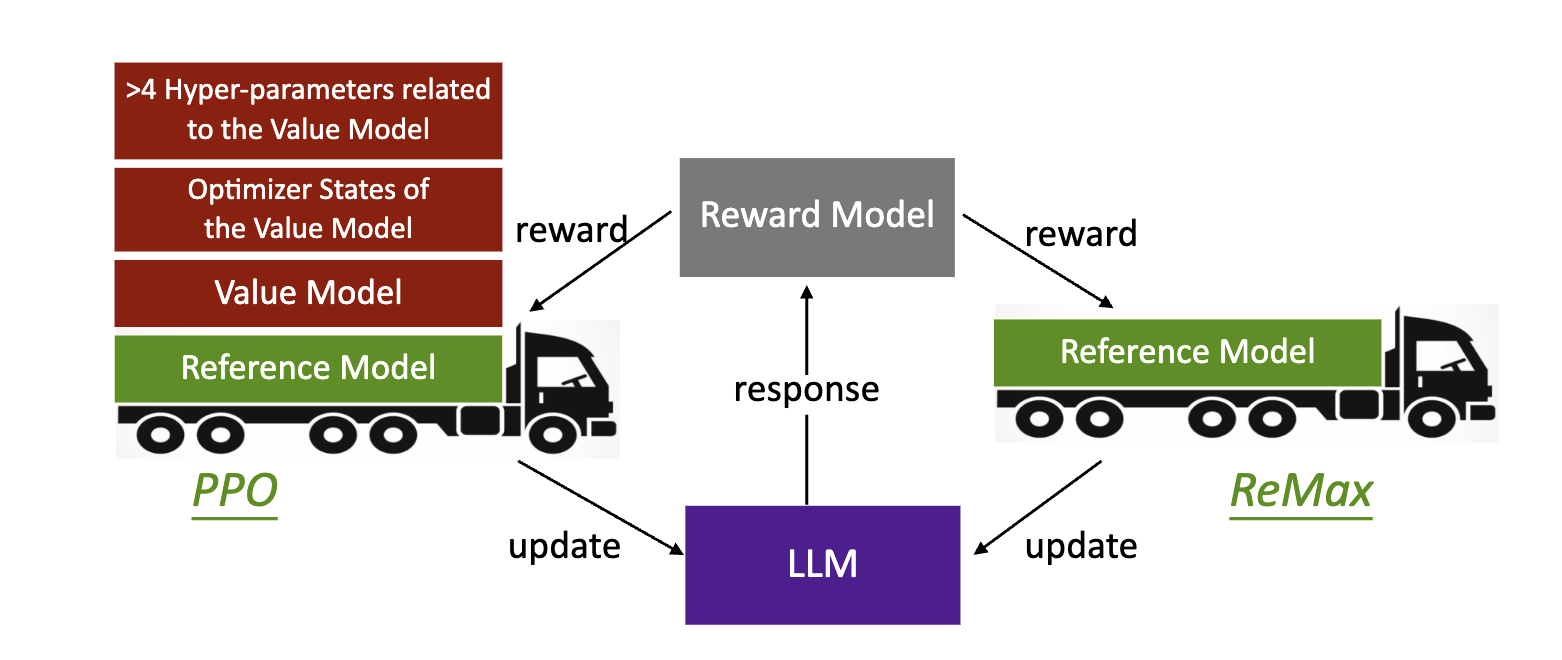
ReMax: A Simple, Effective, and Efficient Reinforcement Learning Method for Aligning Large Language Models
Ziniu Li, Tian Xu, Yushun Zhang, Zhihang Lin, Yang Yu, Ruoyu Sun, Zhi-Quan Luo
The 41st International Conference on Machine Learning (ICML), 2024
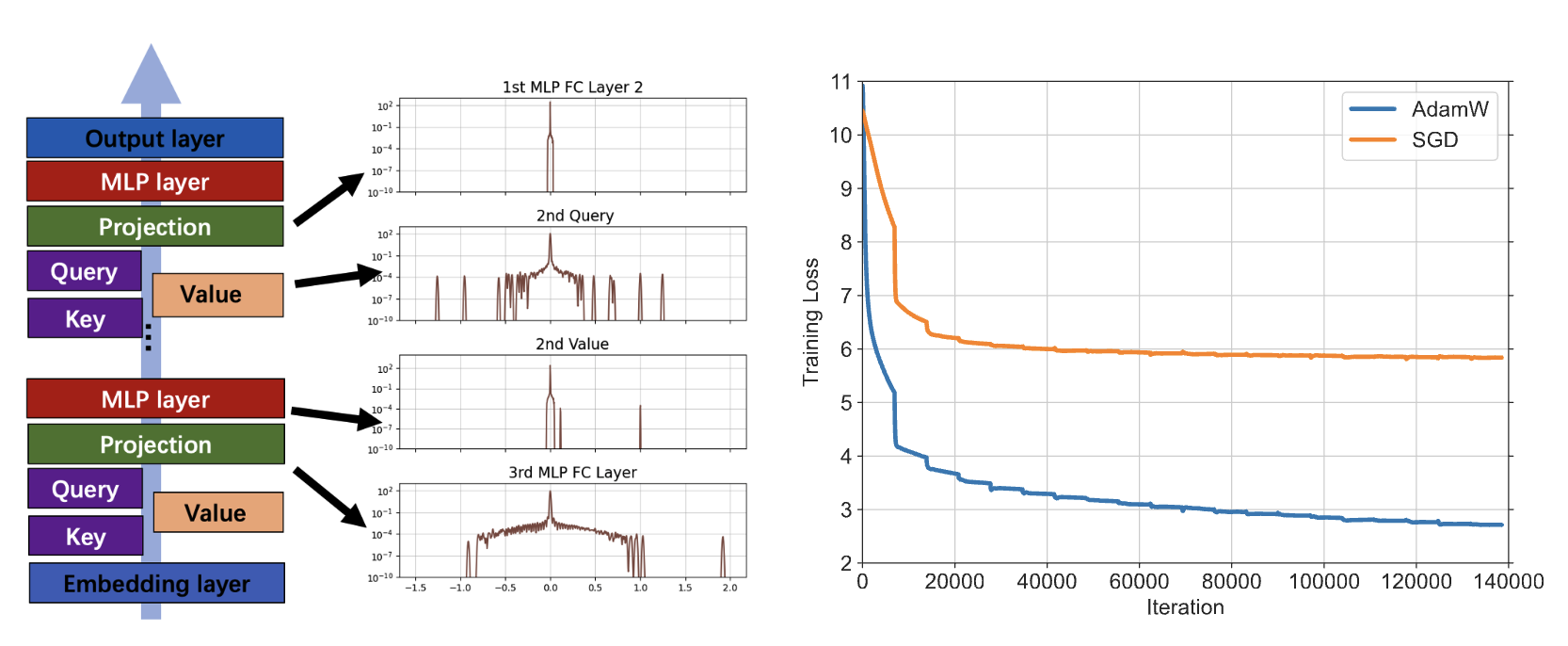
Why Transformers Need Adam: A Hessian Perspective
Yushun Zhang, Congliang Chen, Tian Ding, Ziniu Li, Ruoyu Sun, Zhi-Quan Luo
Conference on Neural Information Processing System (NeurIPS) 38, 2024
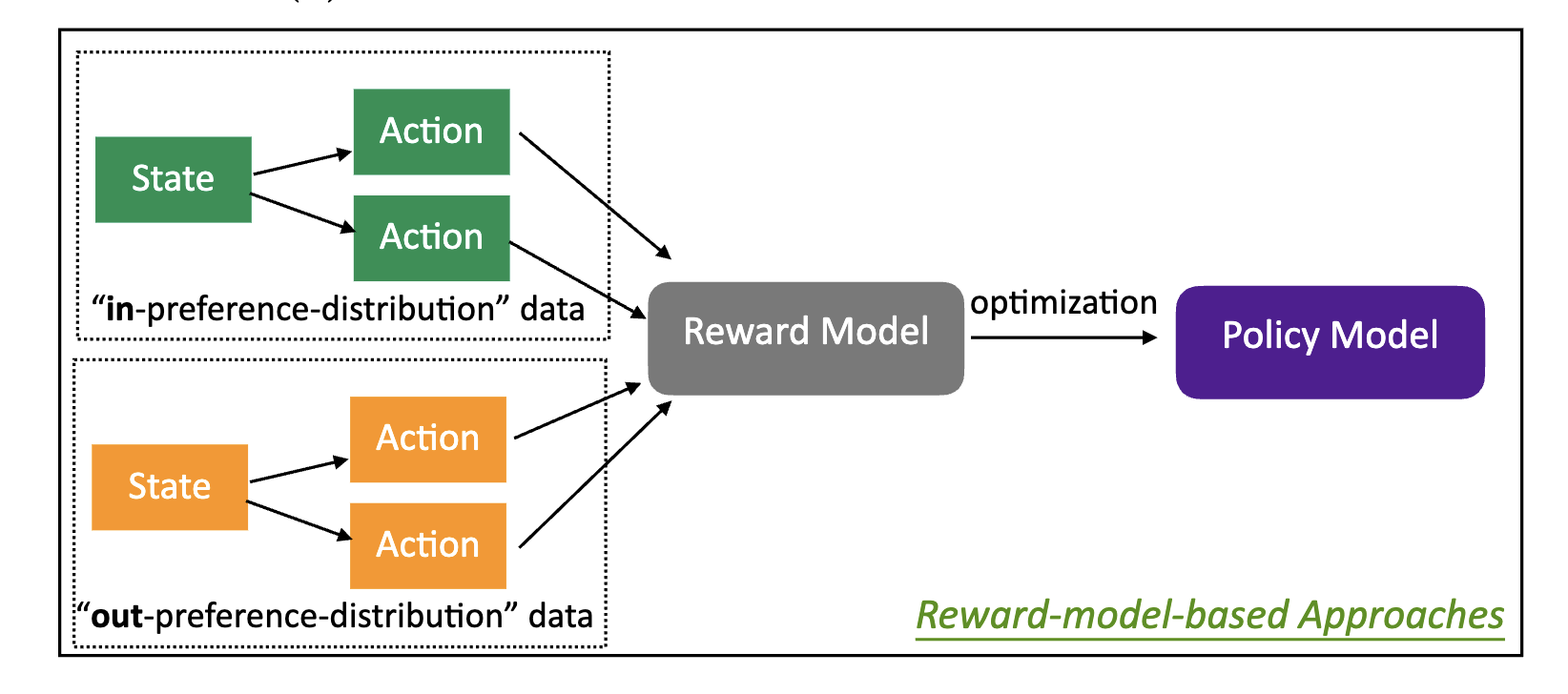
When is RL better than DPO in RLHF? A Representation and Optimization Perspective
Ziniu Li*, Tian Xu*, Yang Yu
The 12th International Conference on Learning Representations (ICLR) (Tiny Paper Track), 2024
(Oral presentation, with an early version at arXiv:2312.10584)
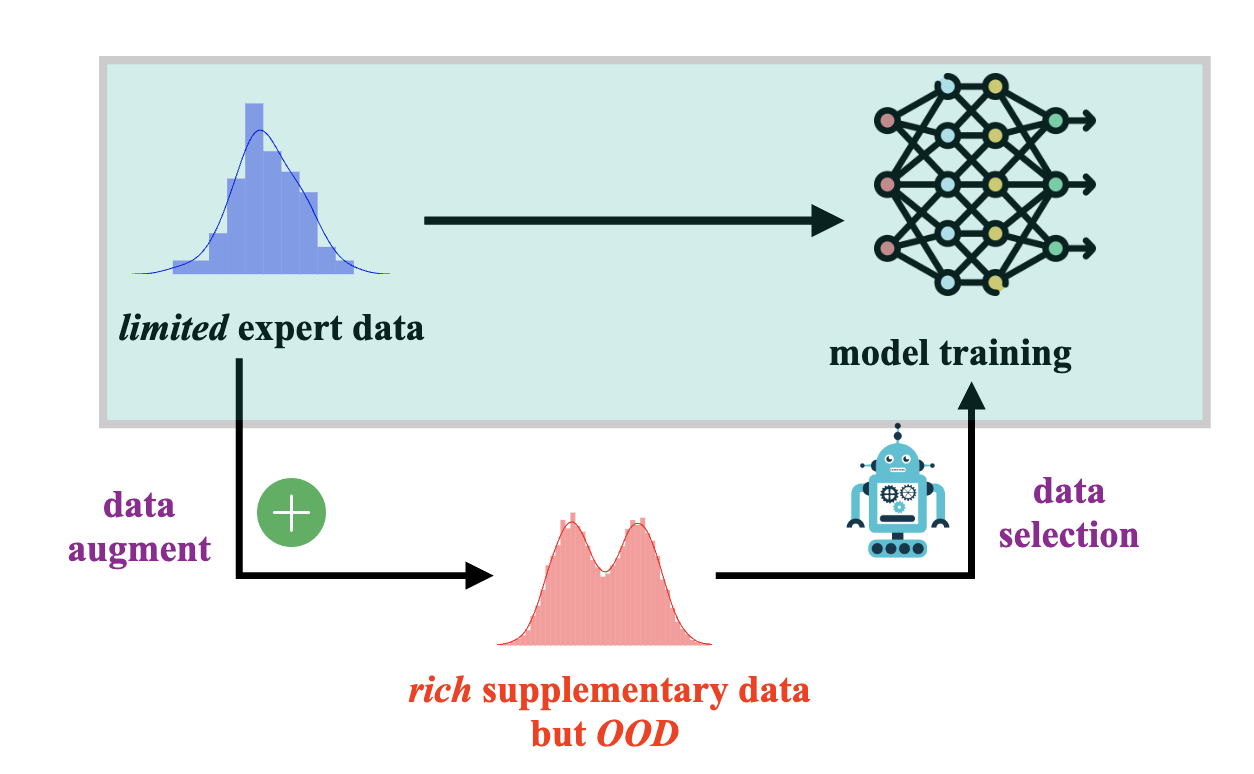
Imitation Learning from Imperfection: Theoretical Justifications and Algorithms
Ziniu Li*, Tian Xu*, Zeyu Qin, Yang Yu, Zhi-Quan Luo
Conference on Neural Information Processing System (NeurIPS) 37, 2023
(Spotlight presentation)
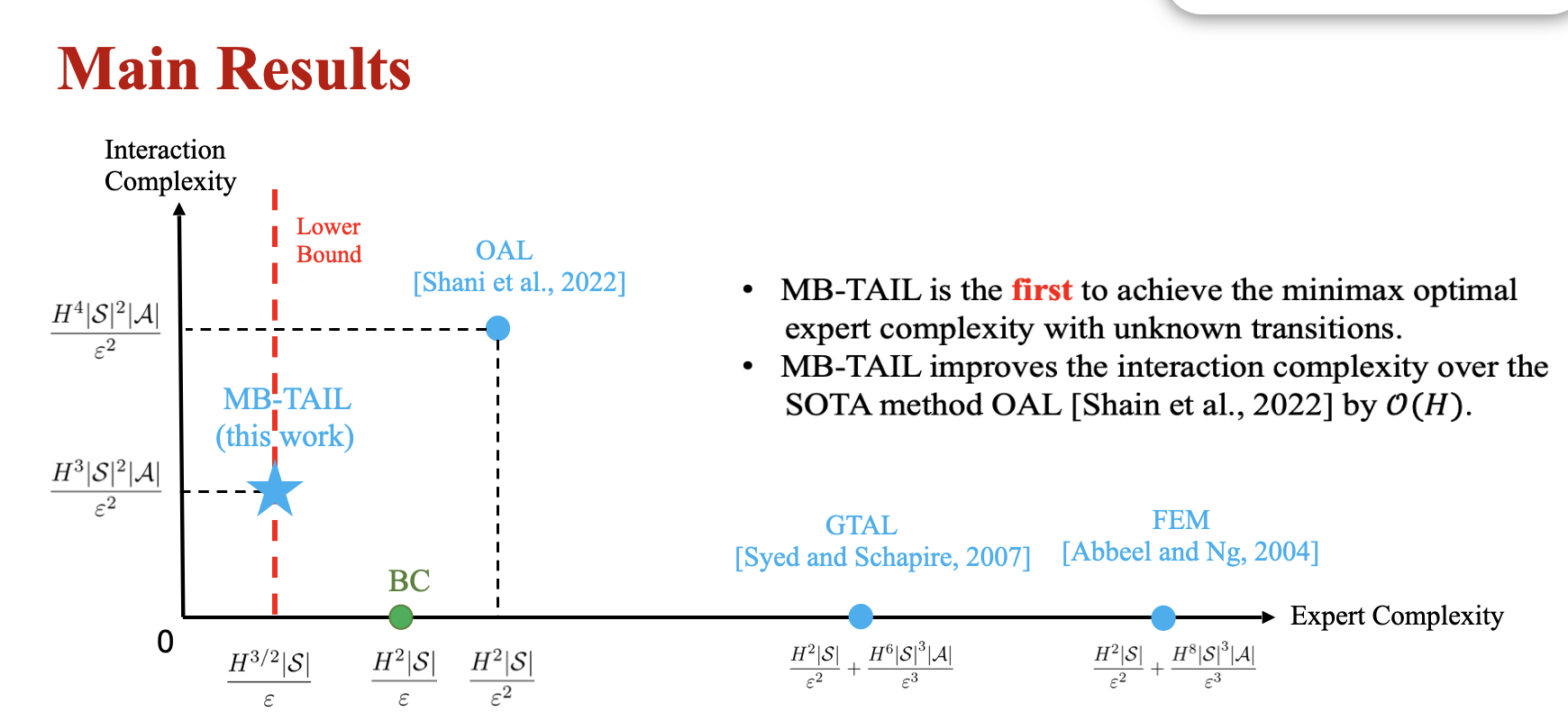
Provably Efficient Adversarial Imitation Learning with Unknown Transitions
Tian Xu*, Ziniu Li*, Yang Yu, Zhi-Quan Luo
The 39th Conference on Uncertainty in Artificial Intelligence (UAI), 2023
(Oral presentation, with an early version at arXiv:2106.10424v2)
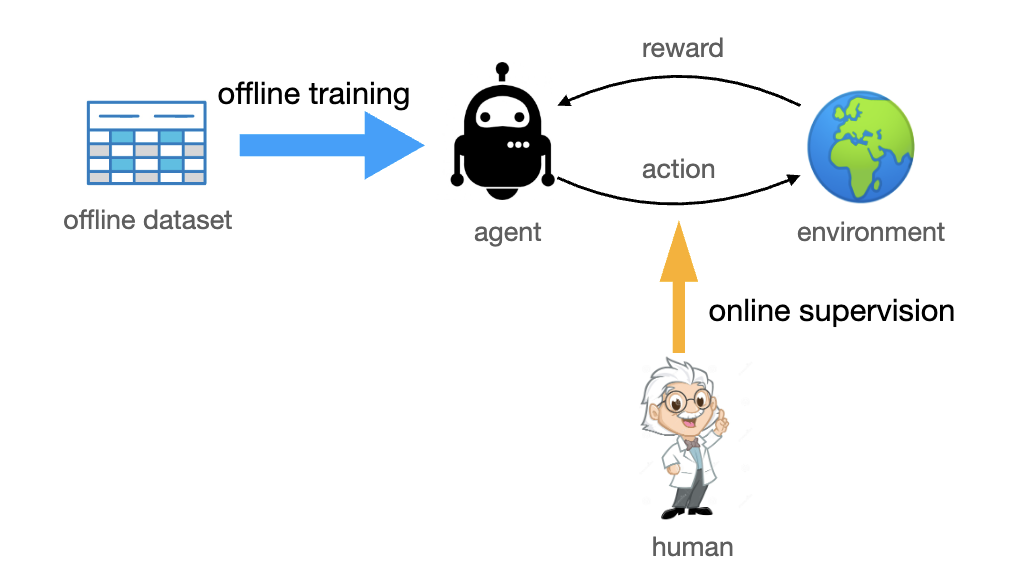
Deploying Offline Reinforcement Learning with Human Feedback
Ziniu Li, Ke Xu, Liu Liu, Lanqing Li, Deheng Ye, Peilin Zhao
arXiv:2303.07046
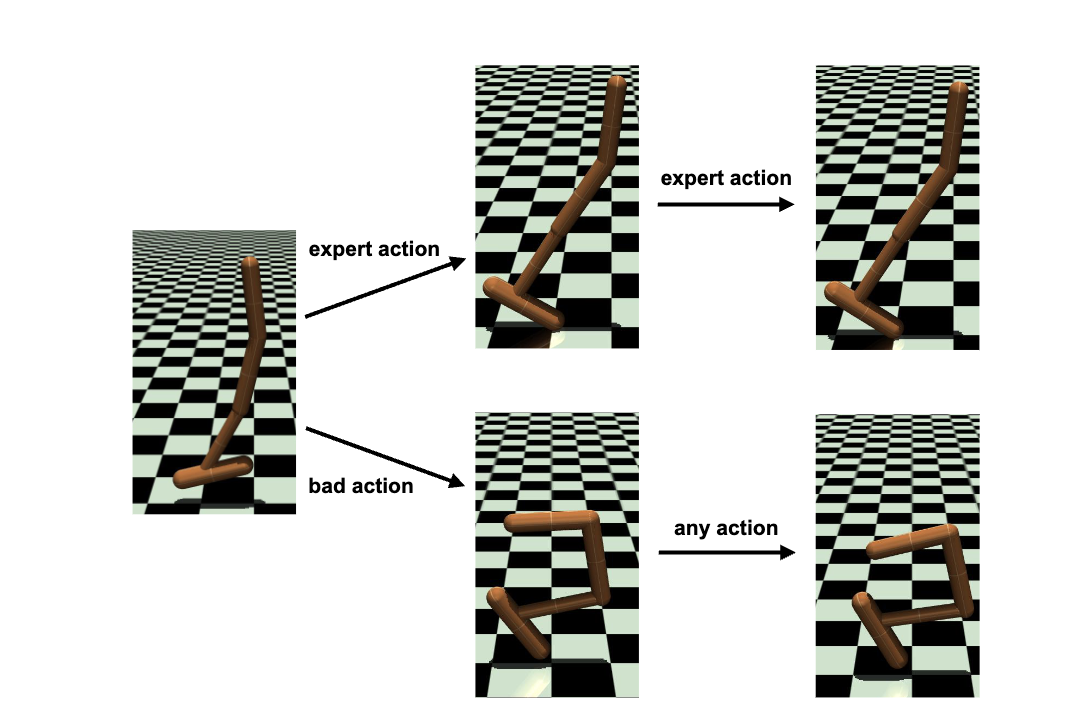
Understanding Adversarial Imitation Learning in Small Sample Regime: A Stage-coupled Analysis
Tian Xu*, Ziniu Li*, Yang Yu, Zhi-Quan Luo
arXiv:2208.01899
(The early version of this work is at arXiv:2106.10424v3)
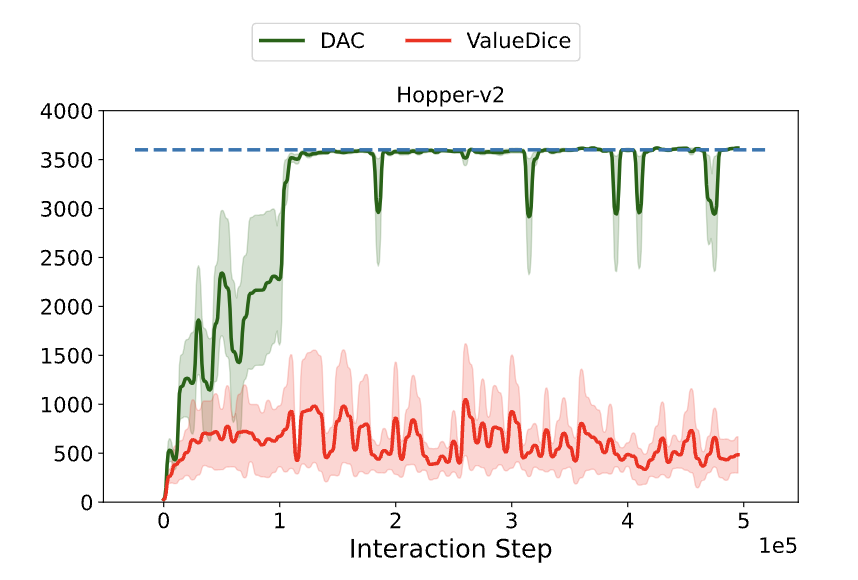
Rethinking ValueDice: Does It Really Improve Performance?
Ziniu Li*, Tian Xu*, Yang Yu, Zhi-Quan Luo
The 10th International Conference on Learning Representations (ICLR) (Blog Track), 2022
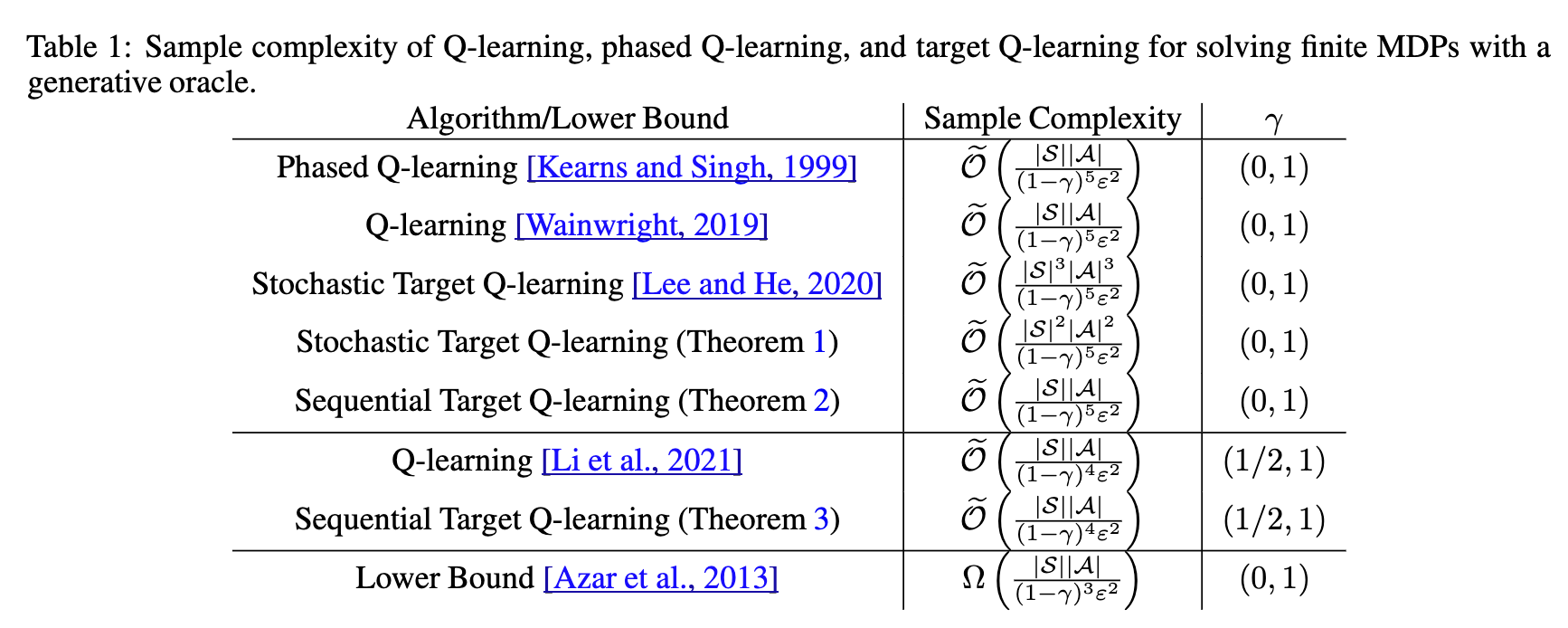
A Note on Target Q-learning for Solving Finite MDPs with A Generative Oracle
Ziniu Li*, Tian Xu*, Yang Yu
arXiv:2203.11489
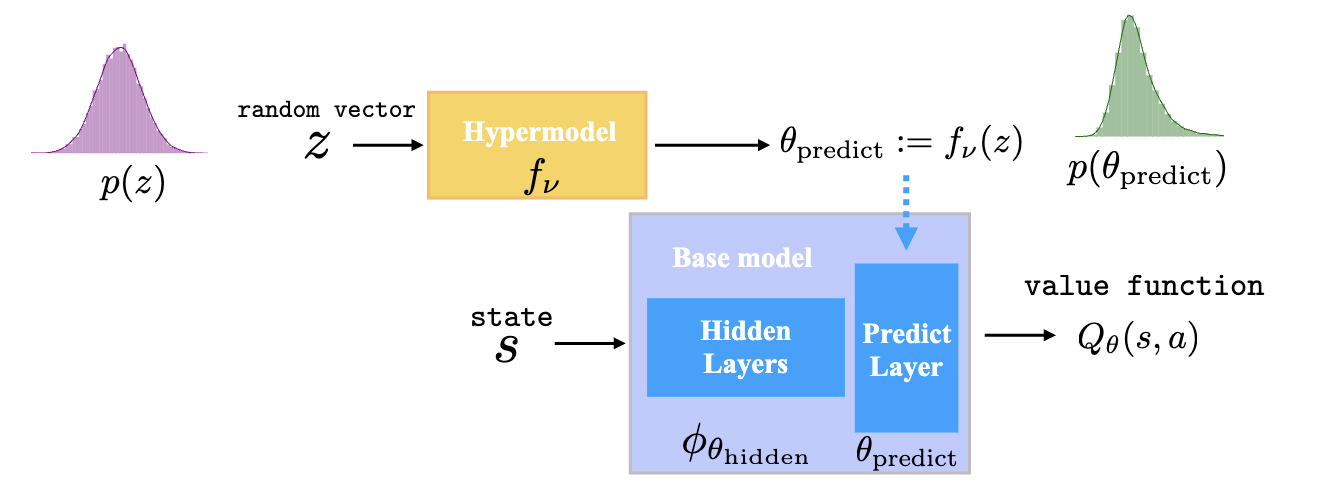
HyperDQN: A Randomized Exploration Method for Deep Reinforcement Learning
Ziniu Li, Yingru Li, Yushun Zhang, Tong Zhang, Zhi-Quan Luo
The 10th International Conference on Learning Representations (ICLR), 2022
(Oral presentation at Workshop on Ecological Theory of Reinforcement Learning at NeurIPS, 2021)

A Concise Introduction to Imitation Learning (In Chinese)
Tian Xu, Ziniu Li, Yang Yu
Online Available
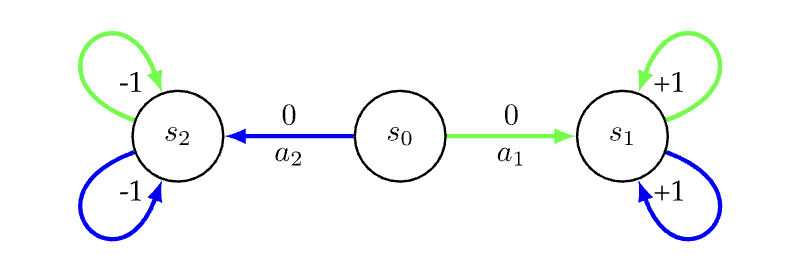
Error Bounds of Imitating Policies and Environments for Reinforcement Learning
Tian Xu, Ziniu Li, Yang Yu
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2021
Error Bounds of Imitating Policies and Environments
Tian Xu, Ziniu Li, Yang Yu
Conference on Neural Information Processing Systems 34 (NeurIPS), 2020
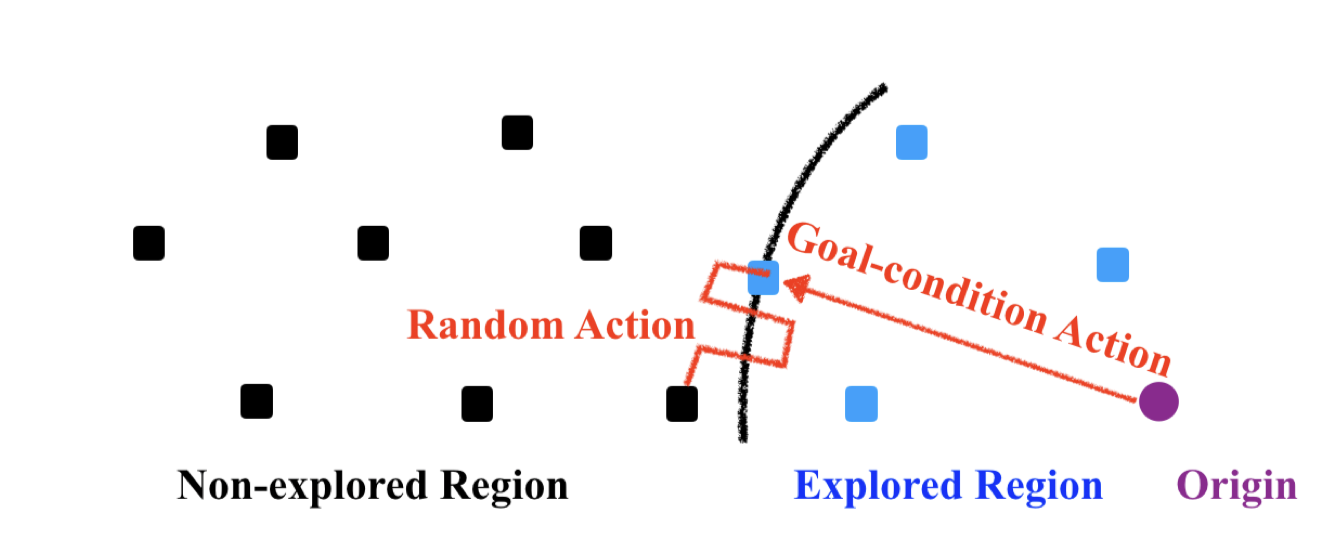
Efficient Exploration by Novelty-pursuit
Ziniu Li*, Xiong-Hui Chen*
The 2nd International Conference on Distributed Artificial Intelligence (DAI), 2020
Self-Guided Evolution Strategies with Historical Estimated Gradients
Fei-yu Liu, Ziniu Li, Chao Qian
The 29th International Conference on Joint Artificial Intelligence (IJCAI), 2020